Under the Hood of XAI Router
Posted July 3, 2025 ‐ 11 min read
More than an AI API router: the control plane for enterprise AI operations.


Enterprise AI is no longer about whether you can call a model API. It is about whether AI can be distributed, governed, secured, measured, and optimized like any other core business resource.
That is why leadership teams are shifting their focus away from “which model is smartest” and toward harder operational questions:
- Who is using AI across the company?
- Which teams deserve more AI tokens and which ones need tighter limits?
- Are upstream API keys scattered across laptops, scripts, and CI jobs?
- Which workloads should run on premium models and which should be routed to cheaper ones?
- Can finance, IT, and business leaders see the same usage picture without fighting over spreadsheets?
Recent public research makes those pressures hard to ignore:
- Microsoft’s 2024 Work Trend Index reported that 75% of knowledge workers already use AI at work, and 78% of them are bringing their own AI tools.
- Microsoft’s 2025 Work Trend Index framed AI as an organizational capacity problem, not just an experimentation topic, as leaders face both productivity pressure and workforce constraints.
- IBM’s 2025 CEO Study found that only 25% of AI initiatives delivered expected ROI and only 16% scaled enterprisewide.
- Deloitte’s 2025 board governance research found that only one quarter of respondents were satisfied with the pace of AI adoption, while nearly one third said their organizations were still not ready to deploy AI.
This is the real context for XAI Router. It is not just a request forwarder. It is the layer that turns fragmented AI usage into a governed enterprise system.
The Big Picture: Three Layers, Not One Proxy
From a product architecture perspective, XAI is best understood as a coordinated multi-component system with three layers:
- Control plane: responsible for account trees, policy configuration, AI token distribution, product and quota systems, billing analytics, and management portals.
- Runtime routing plane: responsible for model mapping, key pool scheduling, rate limiting, ACL enforcement, usage metering, async persistence, and cache orchestration.
- Bridge plane: responsible for translating OpenAI-compatible traffic, Claude Code, Codex Responses, Gemini native APIs, and similar protocols into one governable enterprise entry point.
Put together, these layers give an enterprise much more than a proxy URL. They provide an operating system for AI access.
1. High Performance & Scalability: First Make It Real-World Ready
XAI Router is not tuned for demo traffic. It is tuned for real organizations with employees, internal apps, IDE tools, scheduled jobs, and autonomous agents all sharing the same AI resource pool.
- Rust-native async runtime: the core gateway and bridge components are built for low tail latency, high throughput, and efficient memory usage.
- Strictly layered cache path: across the XAI control and routing stack, hot state such as users, policies,
ModelMapper, andLevelMapperfollows a deliberate read path of memory first, Redis second, database last. - Runtime exact cache:
ModelMapperandLevelMapperdo not act like static config lookups only. They also accumulate exact-match runtime cache to reduce repeated wildcard matching on hot paths. - Stateless horizontal scaling: gateway instances stay stateless while shared state lives in Redis and PostgreSQL, making scale-out straightforward behind a load balancer.
- Asynchronous accounting path: usage updates, logs, billing aggregation, and other non-critical persistence work are pushed off the request hot path whenever possible.
If AI is going to become part of daily enterprise workflows, speed is not a luxury. It is a prerequisite for adoption.
2. Reliability & Intelligent Routing: Availability Must Be the Default
Enterprises do not mainly fear a slightly slow response. They fear the moment AI becomes unavailable during business-critical workflows.
That is why XAI Router is designed to break the fragility of depending on a single key, a single model, or a single provider:
- Round-robin key pools: multiple upstream keys can sit behind the same model or level, and requests can be distributed across them to reduce rate-limit pressure on any one credential.
- Automatic failover and transparent retry: when upstream returns temporary errors such as
429or5xx, the router can retry with the next healthy key automatically. - Cross-level failover: when an entire level becomes unhealthy, traffic can be shifted to a backup level so critical workloads do not stall.
- Real-time configuration sync: adding keys, changing model mappings, or updating account policies can propagate quickly across the cluster without manual restarts.
- Bridge-layer resilience: dedicated adapters for ecosystems such as Codex, Claude, and Gemini let enterprises centralize protocol differences at one governance point instead of re-implementing them in every client.
For leadership, the implication is simple: AI stops being a fragile individual tool and starts becoming a dependable business service.
3. The Bridge Layer: Unifying Codex, Claude, Gemini, and More
Supporting only a generic OpenAI endpoint is not enough once an organization starts using real-world AI tooling.
One of the most important differentiators in this stack is that official tool ecosystems can also be brought under the same governance boundary:
- Codex bridge components handle Codex CLI and Responses traffic, support OpenAI-compatible interfaces, native Responses passthrough, OAuth token rotation, token cache, and model mapping while improving session and cache coordination.
- Claude bridge components connect Claude Code CLI, Claude API, Agent SDK, and OpenAI-compatible entry points, including system prompt injection, streaming conversion, and official-account or key-based access.
- Gemini bridge components connect Gemini native APIs with OpenAI-style chat interfaces through unified forwarding, dynamic authentication, and multi-protocol adaptation.
- Unified policy enforcement: the bridge layer is not isolated. It ultimately sits behind the same governance controls, so
allow_models,model_mapper,level_mapper, rate limits, and billing logic stay consistent across providers.
This separation matters. Teams can keep using different AI tools, while the company keeps one governance model.
4. AI Token Allocation: Turning AI into an Operable Internal Resource
One of the easiest ways for enterprise AI to go off the rails is poor resource distribution.
Many organizations start with a crude process: give someone a key, buy another one when usage spikes, and try to reconcile costs later. The result is predictable:
- no reliable cost attribution
- no planned budget allocation
- no distinction between baseline usage and temporary top-ups
- no shared view of which teams consume what
XAI Router addresses this by treating AI tokens and credits as allocatable enterprise resources rather than vague API consumption:
- Parent and child account distribution: the owner account can create sub-accounts for departments, teams, projects, or individual employees.
- DNA-style inheritance tree: governance boundaries flow downward through an unlimited account hierarchy. Lower levels may narrow access but should not expand beyond upstream boundaries.
- Policy distribution, not just balance distribution: accounts can receive not only credits but also
allow_models,model_mapper,level_mapper, role, level, daily limits, and rate limits. - Productized supply model: XAI separates subscriptions, pay-as-you-go cards, add-ons, and service products to support different allocation and replenishment patterns.
- Hard daily boundaries:
daily_limit, RPD, TPD, TPM, and similar controls let enterprises cap both budget drift and burst traffic.
From a management perspective, AI usage should be handled like cloud spend, bandwidth, or SaaS seats: procured, allocated, tracked, and reclaimed.
5. API Key Governance: Keys Are Production Assets, Not Config Strings
Most enterprise AI risk eventually collapses into one question: who actually controls the upstream credentials?
If every employee directly holds provider keys, the organization immediately inherits several problems:
- keys spread across scripts, IDEs, browsers, and CI pipelines
- offboarding becomes difficult because nobody is sure which credentials remain active
- teams share one provider key, making attribution and audit nearly impossible
- a leaked key can stay active long before finance notices the bill
XAI Router is designed to separate “who can use AI” from “who can see upstream key material”:
- BYOK with centralized governance: the enterprise still uses its own provider keys, but those keys do not have to be redistributed to every endpoint.
- Encrypted storage at rest: upstream credentials are stored in protected form, reducing exposure if the database is accessed.
- Minimum exposure principle: employees and sub-accounts usually receive XAI access credentials, not raw OpenAI, Anthropic, or Google keys.
- ACL security pipeline: authentication, IP allowlists, model allowlists, resource allowlists, account status, and quota checks run as a layered policy chain.
- Bridge-layer token rotation: bridge components also handle OAuth refresh, cache, and secure forwarding for official-account workflows.
For many executives, the requirement is actually straightforward: do not let dozens of employees keep raw third-party keys in uncontrolled places.
6. Metering, Auditability, and Daily Workforce Visibility
If leadership cannot see AI usage every day, then AI is not really being managed.
The XAI management experience is already moving well beyond a basic balance page and toward an operational AI console:
- Today’s quota status: visibility into daily RPD, TPD, daily credit usage, and add-on card progress.
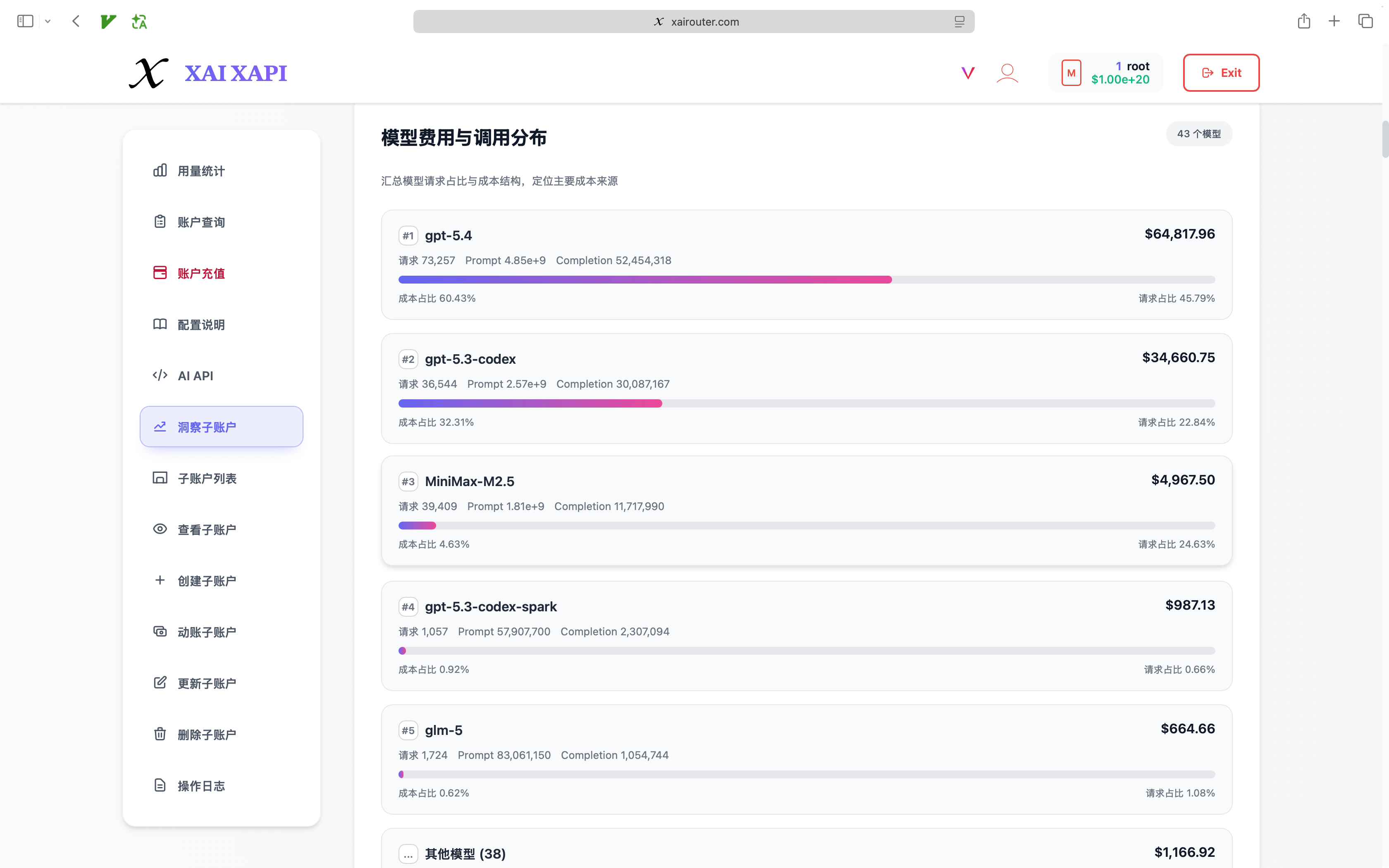
- Per-user and per-model breakdowns: request volume, token usage, and spend can be analyzed by employee, sub-account, and model.
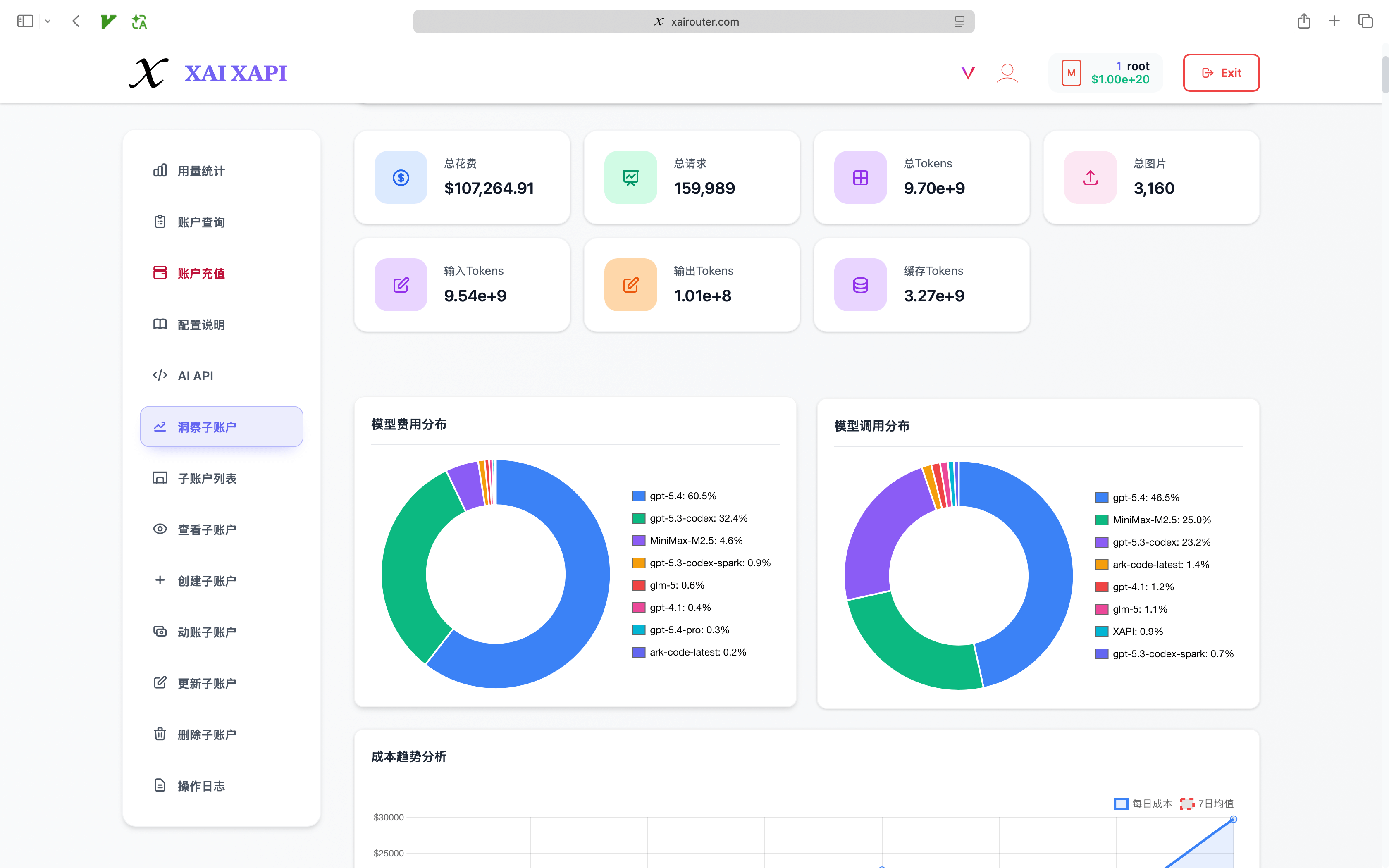
- Billing insight panels: dashboards expose total cost, total requests, total tokens, prompt tokens, completion tokens, cache tokens, image usage, and related metrics.
- Model distribution and trend charts: management can see which models drive budget, where traffic concentrates, and where routing policy should be optimized.
- Sub-account rankings and anomaly detection: comparing teams and users over the same time window makes waste and abnormal spikes easier to spot.
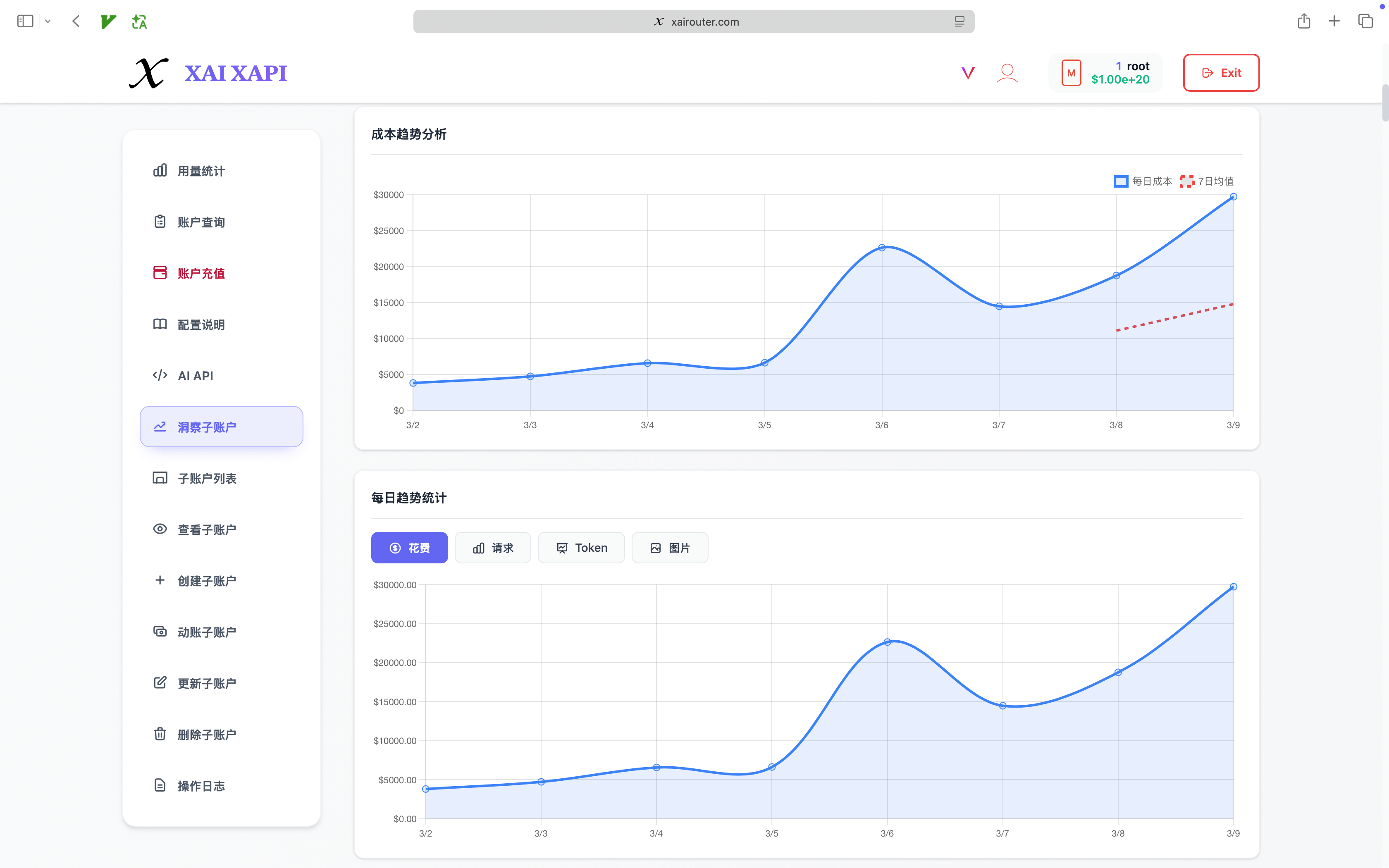
- Daily billing timelines: monthly totals can be drilled down into day-by-day usage to align with releases, campaigns, or workload shifts.
The underlying usage model is also more detailed than a simple request counter. Internally, the system already tracks structures such as:
prompt_tokenscompletion_tokensreasoning_tokenscached_tokens- model-level usage breakdowns
That makes it possible to answer higher-value questions:
- Which departments are using AI effectively?
- Which workloads benefit from cache-heavy request patterns?
- Which tasks truly require premium models?
- Which teams are burning budget without corresponding output?
The goal is not to generate prettier charts. The goal is to create a closed-loop operating model.
7. From the CEO or GM Perspective, This Is a Business System
If you compress the leadership concern set into a few sentences, it usually looks like this:
- AI is already inside the company, but usage is fragmented and hard to govern.
- Budgets are rising, but ROI is still unclear.
- Employees use different tools, yet the company lacks one consistent control model.
- API keys are sensitive, but sharing still happens manually.
- Leadership wants productivity gains, but lacks a daily operating dashboard.
XAI Router answers those concerns with one continuous chain rather than isolated features:
- unified entry point for all AI traffic
- unified identity and organizational structure so requests map back to people and teams
- unified policy model for permissions, limits, and budget boundaries
- unified routing across models, providers, and official tool ecosystems
- unified metering for tokens, requests, search, image, cache, and spend
- unified operations view so IT, finance, and business leaders each get the layer they need
That is when AI stops being an unmanaged departmental experiment and becomes an operable productivity system.
Conclusion: More Control Tower Than Simple Gateway
The architectural value of XAI Router lies in combining performance, routing, security, allocation, metering, and organizational governance inside one coherent platform.
For developers, it is absolutely a high-performance AI API router.
For management, it is closer to:
- a unified AI access hub
- an AI token allocation system
- an API key governance layer
- a workforce analytics and AI budget operations platform
Once an enterprise starts using OpenAI, Anthropic, Gemini, DeepSeek, MiniMax, Codex, Claude Code, Agent SDKs, and other tooling at the same time, this combination of a unified control plane, multi-protocol bridges, and granular metering becomes the practical path to scale.
XAI Router is not built merely to make requests go through. It is built so the organization can know who is using AI, how they are using it, who should get more resources, where boundaries must tighten, and how AI investment translates into durable operating leverage.