What Happens When Multiple AI Agents Build Relationships?
Posted February 6, 2026 by XAI Tech Team ‐ 5 min read

On Feb 6, 2026 (Beijing Time, UTC+8), OpenAI announced OpenAI Frontier: a platform for enterprises to build, deploy, and manage AI co-workers that can complete real work, with a strong focus on identity, permissions, and boundaries. This underscores how identity infrastructure is becoming a core capability for agent platforms.
But the bigger goal is not to "hire a batch of plug-and-play AI colleagues." It is to cultivate the most fertile soil for virtual lives to grow. Every agent is planted here and evolves through tasks, domain knowledge, and feedback. It can collaborate with other agents and create its own sub-agents, gradually forming a self-propagating ecosystem.
To make that growth real, the first requirement is to turn relationships into a native system capability. That is exactly what Account DNA is built for.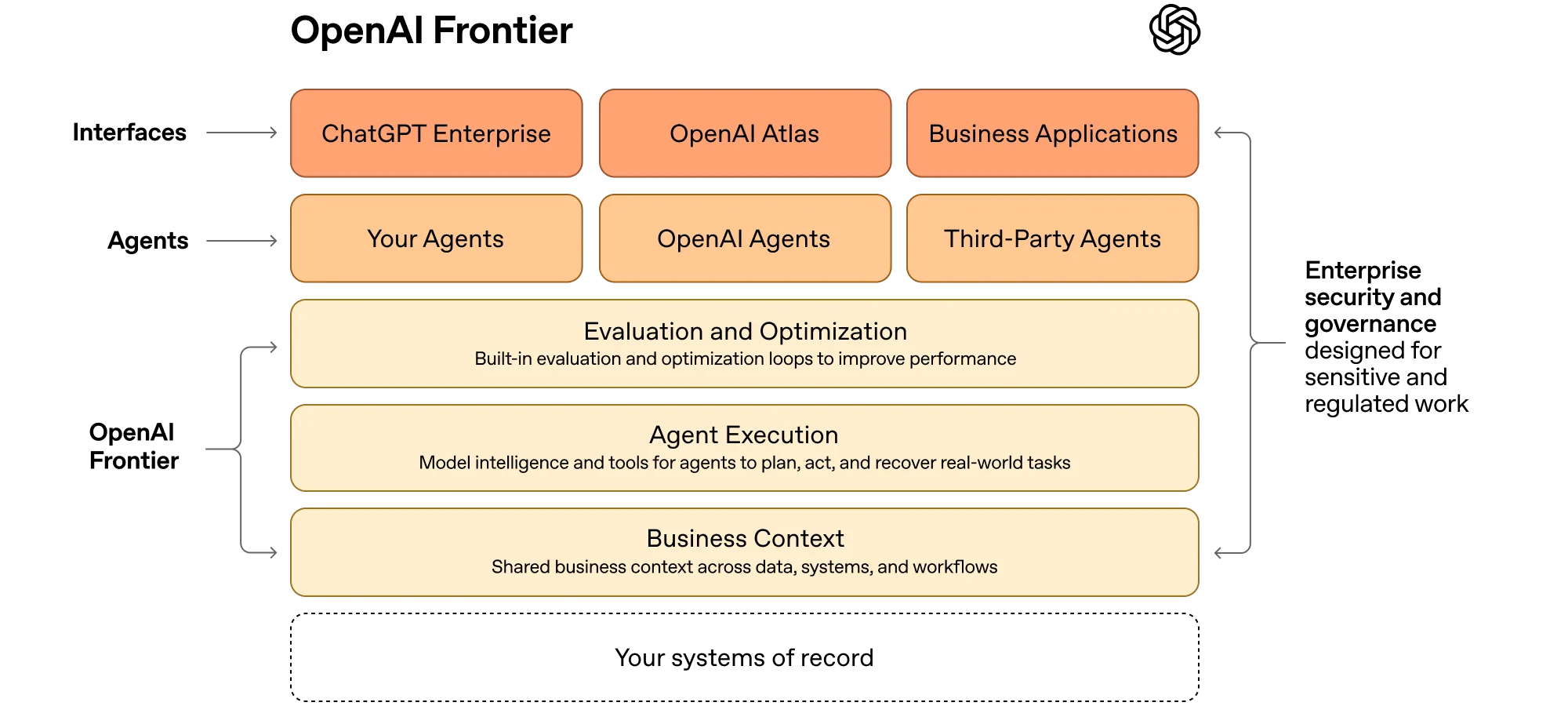
The hard part of the Agent era is not "can it run tasks," but "who are you, where do you come from, and whom can you represent?" When multiple agents begin to collaborate, hand off, and call each other, identity relationships move from back-office configuration to a first-class primitive:
- Who is the parent agent, and who is the child agent?
- Which permissions are inherited, and which require explicit re-authorization?
- Are two agents part of the same "family," and can they share budgets and model quotas?
That is the core of the question: "What happens when multiple AI agents form relationships?" One practical answer: make relationships themselves verifiable, queryable, and inheritable DNA.
1) What is Account DNA: making relationships computable
Account DNA is a string path that describes lineage:
.
.1.
.1.42.
.1.42.102.It is not a hash. It is a structured genealogy path. The convention is simple:
- The
rootaccount DNA is"." - A child account DNA = parent DNA + parent ID +
"."
In code, the rule is explicit:
// Child account DNA inherits the parent's lineage path
user.DNA = fmt.Sprintf("%s%d.", parentUser.DNA, parentUser.ID)A plain string becomes the unified encoding of relationships across the entire system.
2) A visual example: the account family tree
This tree makes the DNA meaning obvious at a glance:
Root (ID: 1)
DNA: "."
|
+---------------------------+---------------------------+
| |
User A (ID: 2) User B (ID: 3)
DNA: ".1." DNA: ".1."
| |
+-----------+-----------+ +-----------+-----------+
| | | |
User C (ID: 4) User D (ID: 5) User E (ID: 6) User F (ID: 7)
DNA: ".1.2." DNA: ".1.2." DNA: ".1.3." DNA: ".1.3."
| | | |
+---+---+ +---+---+ +---+---+ +---+---+
| | | | | | | |
User G User H User I User J User K User L User M User N
(ID: 8) (ID: 9) (ID: 10) (ID: 11) (ID: 12) (ID: 13) (ID: 14) (ID: 15)
DNA: DNA: DNA: DNA: DNA: DNA: DNA: DNA:
".1.2.4." ".1.2.4." ".1.2.5." ".1.2.5." ".1.3.6." ".1.3.6." ".1.3.7." ".1.3.7."
|
|
O (ID: 16)
DNA: ".1.3.7.15."From this example you can read:
User Chas DNA.1.2., which means it comes fromRoot(1)→User A(2)User Ohas DNA.1.3.7.15., which means it comes fromRoot(1)→User B(3)→User F(7)→User N(15)
3) Why relationship checks are so fast: ancestry can be decided in one match
The key value of DNA is that relationship checks collapse into string operations:
func isAncestor(ancestor, descendant *models.User) bool {
return strings.Contains(descendant.DNA, fmt.Sprintf(".%d.", ancestor.ID))
}- "Is this an ancestor?" One
Contains(approximately O(1) by operation count; O(L) by string length) - "Find all descendants" One SQL prefix match
Where("dna LIKE ?", fmt.Sprintf("%s%d.%%", parent.DNA, pid))This means:
No recursion, no multi-table joins, no extra tree indexes. Relationship checks reduce to string matching and remain stable at scale.
4) Single-tenant mode: one family tree, unified governance
In single-tenant mode, the core idea is: all agents belong to the same tree.
In this design:
- In single-tenant mode,
OIDis fixed at1 - All new users default to
PID=1and DNA.1. - The
rootDNA is., the ancestor of the organization
This gives you:
- A root authority that governs the entire tree
- Clear parent-child paths for consistent inheritance and budgeting
- No "identity chain break" even if a middle node is deleted, because ancestry remains encoded in DNA
In this mode, DNA is a lossless encoding of organizational structure.
5) Multi-tenant mode: one tree, many ecosystems
In multi-tenant mode, each tenant owns its own trunk while still hanging from the system root:
- New registrations default to
DNA = .1., a direct child of root - Its
OIDis set to its own ID after creation, becoming the tenant owner - When the owner creates sub-accounts, DNA grows downward:
.1.<ownerID>.,.1.<ownerID>.<childID>.
Which forms:
root (ID: 1, DNA: .)
├─ Tenant A (ID: 8, DNA: .1.)
│ └─ A1 (DNA: .1.8.)
└─ Tenant B (ID: 12, DNA: .1.)
└─ B1 (DNA: .1.12.)Note: an Owner's own DNA records only the ancestor path and does not include the Owner's own ID. The Owner ID is appended only when creating child accounts.
One tree, many branches: unified management with clear isolation. Console, notifications, analytics, and billing can all enforce boundaries by DNA path.
6) Toward an Agent cloud: DNA as a collaboration protocol
The future agent cloud is not a monolith. It is a large-scale collaboration network:
- One agent calls another agent
- A task is decomposed into multiple sub-agents
- Agents are copied, forked, and recombined like software packages
Without a relationship protocol, scale becomes chaos.
Account DNA plays three roles here:
- Identity lineage: who you descend from and what you inherit
- Security boundaries: shared resources within a branch, re-authorization across branches
- Collaboration governance: aggregate logs, budgets, alerts, and audits by DNA path
In short: DNA makes relationships a native system capability, not a patchwork add-on.
7) Why this design is elegant
- Minimal: one string covers relationships, permissions, analytics, and notifications
- Fast: ancestry is resolved with a single match (approximately O(1) by operation count), while naturally fitting SQL prefix indexing
- Scalable: effectively infinite depth without architectural changes
- Governable: naturally fits multi-tenancy and large-scale collaboration
It supports traditional SaaS account hierarchies and future agent population structures.
Closing: identity infrastructure for the Agent era
As AI agents become nodes in production relationships, identity is no longer just login state; it is the grammar of collaboration. Account DNA gives relationships a computable, inheritable, and governable form.
Today it powers multi-tenant accounts. Tomorrow it becomes the lineage of the agent cloud.