多个 AI Agent 之间发生关系怎么办?
Posted February 6, 2026 by XAI 技术团队 ‐ 8 min read

2026 年 2 月 6 日(北京时间),OpenAI 发布了 OpenAI Frontier:一个面向企业的平台,帮助构建、部署和管理能完成实际工作的 AI 同事,并强调身份、权限与边界的体系化建设。这也说明,身份基础设施正在成为 Agent 平台的核心能力。
但更进一步的问题,不是“雇佣一批即插即用的 AI 同事”,而是如何打造一片最适合虚拟人生长的沃土:每个 Agent 在这里落地,随着任务、业务知识和反馈不断成长;既能与其他 Agent 建立协作关系,也能创建自己的子 Agent,逐步形成一个自我繁衍、自我进化的生态系统。
而要让“生长”真正发生,第一件事就是把关系变成系统的原生能力。这正是账号 DNA 要解决的问题。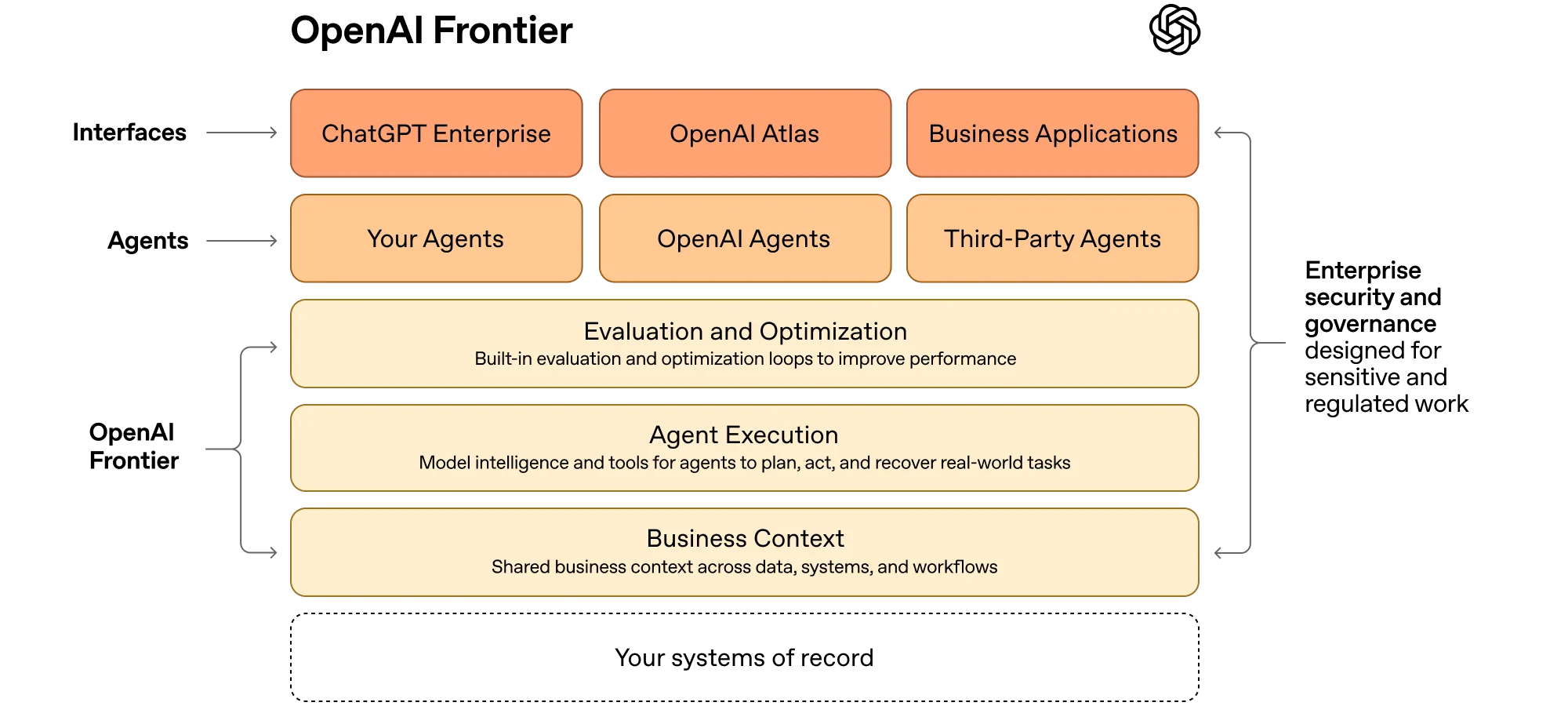
AI Agent 时代真正难的不是“会不会跑任务”,而是“你是谁、你从哪来、你能代表谁”。
当多个 Agent 开始协作、分工、接力、互相调用时,身份关系会从后台配置升级为一等公民:
- 谁是主 Agent,谁是子 Agent?
- 谁的权限是继承来的,谁需要重新授权?
- 两个 Agent 之间是否属于同一“家族”,能否共享预算与模型配额?
这就是“多个 AI Agent 之间发生关系怎么办?”的核心问题。 一种更适合 Agent 协作的答案是:让关系本身成为一种可验证、可查询、可继承的“DNA”。
1) 账号 DNA 是什么:关系的“可计算化”
账号 DNA 是一个用于描述血缘关系的字符串路径:
.
.1.
.1.42.
.1.42.102.它不是哈希,而是结构化的家谱路径。约定非常简单:
root账号的 DNA 为"."- 新子账号的 DNA = 父账号 DNA + 父账号 ID +
"."
在代码里,这条规则是明确的:
// 子账号DNA来自父账号的遗传DNA
user.DNA = fmt.Sprintf("%s%d.", parentUser.DNA, parentUser.ID)于是,一个看似简单的字符串,就成了整个系统里关系的统一编码。
2) 直观示例:一棵账号家谱树
下面这棵“家谱树”能一眼看懂 DNA 的含义:
Root (ID: 1)
DNA: "."
|
+---------------------------+---------------------------+
| |
User A (ID: 2) User B (ID: 3)
DNA: ".1." DNA: ".1."
| |
+-----------+-----------+ +-----------+-----------+
| | | |
User C (ID: 4) User D (ID: 5) User E (ID: 6) User F (ID: 7)
DNA: ".1.2." DNA: ".1.2." DNA: ".1.3." DNA: ".1.3."
| | | |
+---+---+ +---+---+ +---+---+ +---+---+
| | | | | | | |
User G User H User I User J User K User L User M User N
(ID: 8) (ID: 9) (ID: 10) (ID: 11) (ID: 12) (ID: 13) (ID: 14) (ID: 15)
DNA: DNA: DNA: DNA: DNA: DNA: DNA: DNA:
".1.2.4." ".1.2.4." ".1.2.5." ".1.2.5." ".1.3.6." ".1.3.6." ".1.3.7." ".1.3.7."
|
|
O (ID: 16)
DNA: ".1.3.7.15."从这个例子里可以读出:
User C的 DNA 是.1.2.,说明它来自Root(1)→User A(2)User O的 DNA 是.1.3.7.15.,说明它来自Root(1)→User B(3)→User F(7)→User N(15)
3) 关系判断为什么这么快:祖先关系一次匹配即可判定
DNA 的关键价值,是让关系判断变成纯字符串运算:
func isAncestor(ancestor, descendant *models.User) bool {
return strings.Contains(descendant.DNA, fmt.Sprintf(".%d.", ancestor.ID))
}- 判断“是否为祖先”:一次
Contains(按操作次数近似 O(1),按字符串长度为 O(L)) - 查找“所有后代”:一次
LIKE前缀匹配
Where("dna LIKE ?", fmt.Sprintf("%s%d.%%", parent.DNA, pid))这意味着什么?
不需要递归、不需要多表 join、不需要额外索引树。 关系判断可以简化为字符串匹配,在大规模系统里依旧稳定、可扩展。
4) 单租户场景:全员同族、统一秩序
单租户的核心特点是:一个组织内的所有 Agent 都属于同一棵树。
在这套实现里:
- 单租户模式下,
OID固定为1 - 所有新用户的
PID=1,DNA 默认为.1. root的 DNA 是.,它是整个组织的祖先
这意味着:
- 组织管理员拥有“根权限”,可管理整棵树
- 每个 Agent 都有清晰的父子路径,权限继承与预算分配天然一致
- 一个 Agent 被删除,也不会导致“身份断链”,因为 DNA 路径仍保留祖先信息
在这种模式下,DNA 就像企业组织结构的“无损编码”。
5) 多租户场景:一棵树,多个生态分支
多租户模式下,每个租户都拥有自己的“主干”,但仍统一挂在系统根上:
- 新注册用户默认
DNA = .1.,是 root 的直接后代 - 其
OID会在创建后被设置为自身 ID,成为“租户 Owner” - 当该 Owner 创建子账号时,DNA 会继续向下增长:
.1.<ownerID>.、.1.<ownerID>.<childID>.
这就形成了:
root (ID: 1, DNA: .)
├─ Tenant A (ID: 8, DNA: .1.)
│ └─ A1 (DNA: .1.8.)
└─ Tenant B (ID: 12, DNA: .1.)
└─ B1 (DNA: .1.12.)注意:Owner 自身的 DNA 记录的是祖先路径,不包含自身 ID;只有在创建子账号时,才会把 Owner ID 追加进子账号 DNA。
一棵树、多个分支,既能统一管理,又能清晰隔离。 在控制台、通知、统计、计费等场景中,可以直接基于 DNA 路径划定权限边界。
6) 面向 Agent 云平台:DNA 是“身份协作协议”
未来的 Agent 云平台不是“单体 AI”,而是大规模协作网络:
- 一个 Agent 调用另一个 Agent
- 一个任务被拆解为多个 Sub-Agent
- Agent 像软件包一样被复制、派生、再组合
如果没有一种“关系协议”,协作规模上去后会变得不可控。
账号 DNA 在这里扮演三种角色:
- 身份链路:明确你是谁的子孙、你继承了哪些权限
- 安全边界:同 DNA 分支内共享资源,跨分支需重新授权
- 协作治理:按 DNA 路径聚合日志、预算、通知、审计
简而言之:DNA 让“关系”成为系统原生能力,而不是后置补丁。
7) 为什么这套设计精巧
- 极简:一个字符串,覆盖关系、权限、统计、通知
- 高效:祖先关系可由单次匹配完成(按操作次数近似 O(1)),并天然适配 SQL 前缀索引
- 可扩展:理论上无限层级,无需改动架构
- 可治理:天然适配多租户与大规模协作生态
它既能支撑传统的 SaaS 分层账户,也能支撑未来 Agent 的“群体智能结构”。
结语:Agent 时代的“身份基础设施”
当 AI Agent 变成“生产关系”中的节点时,身份不再只是登录态,而是协作的语法。 账号 DNA 让关系具备了可计算、可继承、可治理的形态。
今天它是多租户账号体系; 明天,它就是 Agent 云平台的“协作血缘”。